What The Food
Бот анализа состава продуктов по фото
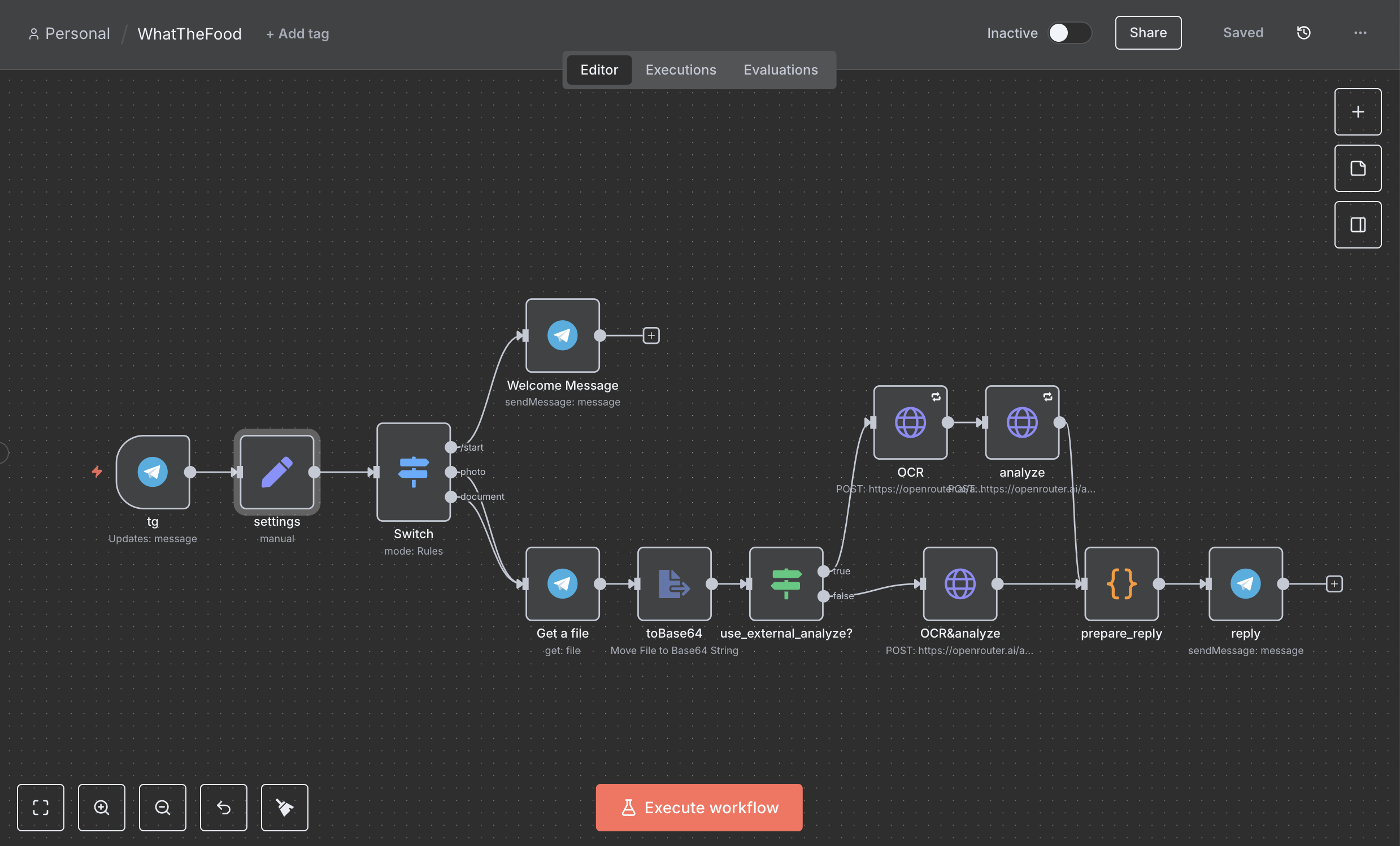
Простой workflow, который принимает фото, распознаёт текст и анализирует состав продукта, модель возвращает результат в заранее описанной JSON структуре (массив ингридиентов с описанием и оценкой вредности, общий итог, и т.п.), далее с помощью JavaScript формируется человекочитаемый ответ с визуальной составляющей (emoji).
Реализовано два варианта работы:
Реализовано два варианта работы:
- распознавание текста и анализ в одном запросе с помощью мультимодальной модели "google/gemma-3-27b-it"
- распознавание текста с помощью мультимодальной модели "google/gemma-3-27b-it", потом анализ состава с помощью модели "openai/gpt-oss-20b"
Ссылка на телеграм бот:
https://t.me/WhatTheFoodBot
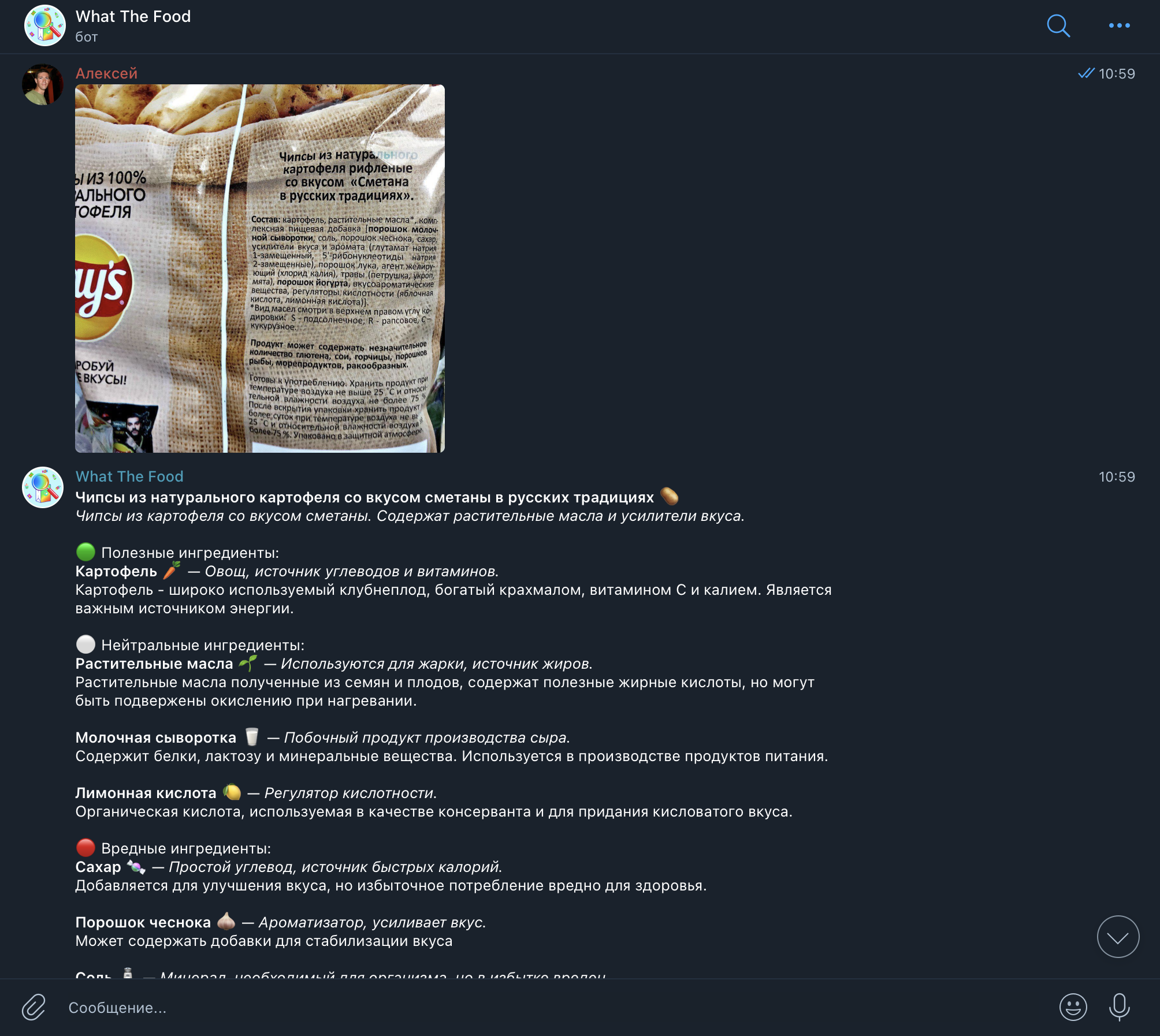
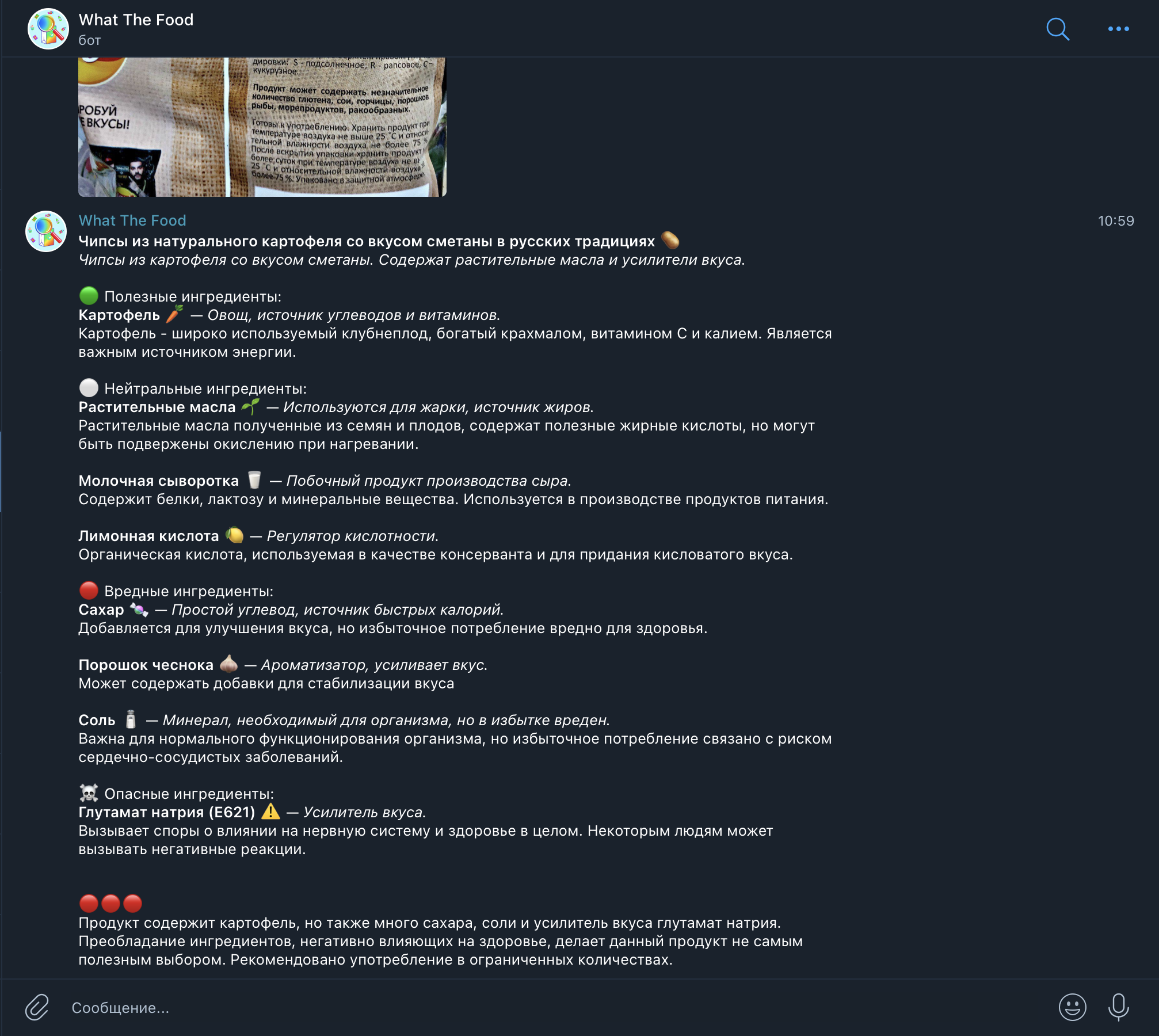
Скриншоты: